Why ke-simple
What makes it different
Content is identity
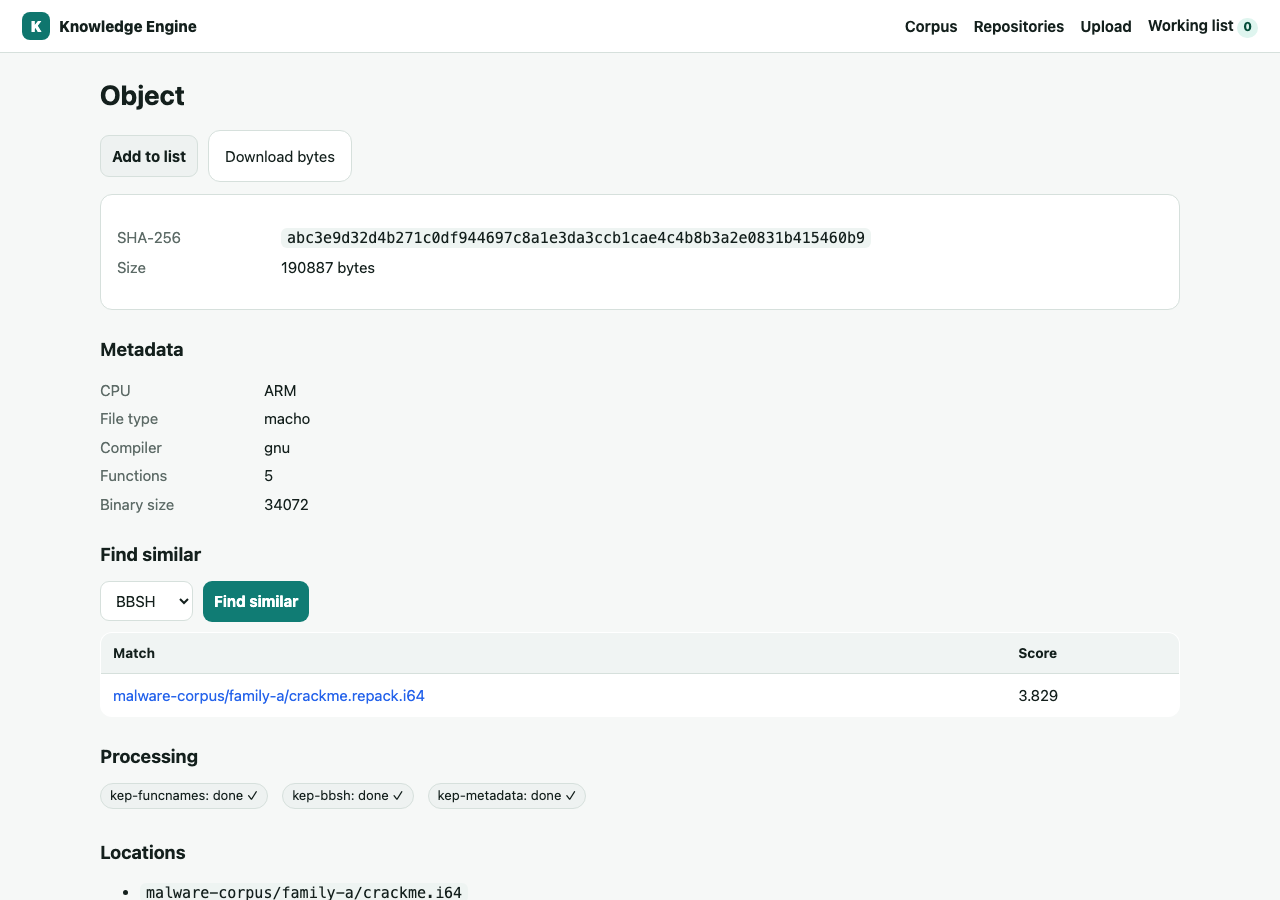
Files are addressed by SHA-256 and stored once — duplicates collapse automatically. Names, buckets, and locations are just mutable metadata around the hash.
One service, one Postgres
No Celery, Meilisearch, ChromaDB, or Redis to run. Full-text and vector search live in Postgres; bytes live on disk. Stand it up with a single command.
Similarity across the corpus
Find functions and binaries that resemble a known sample — by microcode structure, flow-graph embeddings, shared strings, or FLIRT signatures.
Git-native projection
Push binaries and IDBs to a hosted repo; a small .ke/actions.yml maps files into buckets
with tags and processing — one repo can feed many buckets.
Links that self-resolve
An IDB records the source binary it was built from; the link is keyed by content hash and resolves in any ingest order — no back-fill, with tag inheritance.
Hash-addressable API
Pipelines fetch any object's exact bytes by hash over plain HTTP — no UI, no bucket/key needed. The web UI and API share one origin.
Who it's for
- Reverse-engineering teams that want a shared, searchable, de-duplicated corpus of binaries and IDBs instead of scattered folders and ad-hoc naming.
- Malware analysts triaging large sample sets — cluster by similarity, tag by family, and pivot by hash, string, or function name.
- Tooling engineers who need a hash-addressable HTTP corpus to wire into CI, sandboxes, or IDA plugins.
How it fits together
One front door, one datastore. Every ingest path funnels into a single storage service; a reactor turns changes into jobs; workers run extractors and import their results; operations answer queries.
Read the Concepts for the model, or jump to Use cases for concrete workflows.